

{kind=link}
If you are running an AI agent like Hermes on your machine right now, stop and ask yourself one question: what happens if someone else starts talking to it?
Not maliciously. Not through a breach. Just an email with a prompt injection hidden in the fine print, a poisoned GitHub issue your agent reads while triaging tickets, or a dodgy MCP server that looks legitimate. Your agent does not know the difference between a command from you and a command hidden inside a PDF. It just executes.
That is the reality of AI agent security in 2026. Your agent is not a chatbot. It is an employee with system access, running at machine speed, on your infrastructure.
Let me walk through what that actually means for Hermes users and how to lock it down.
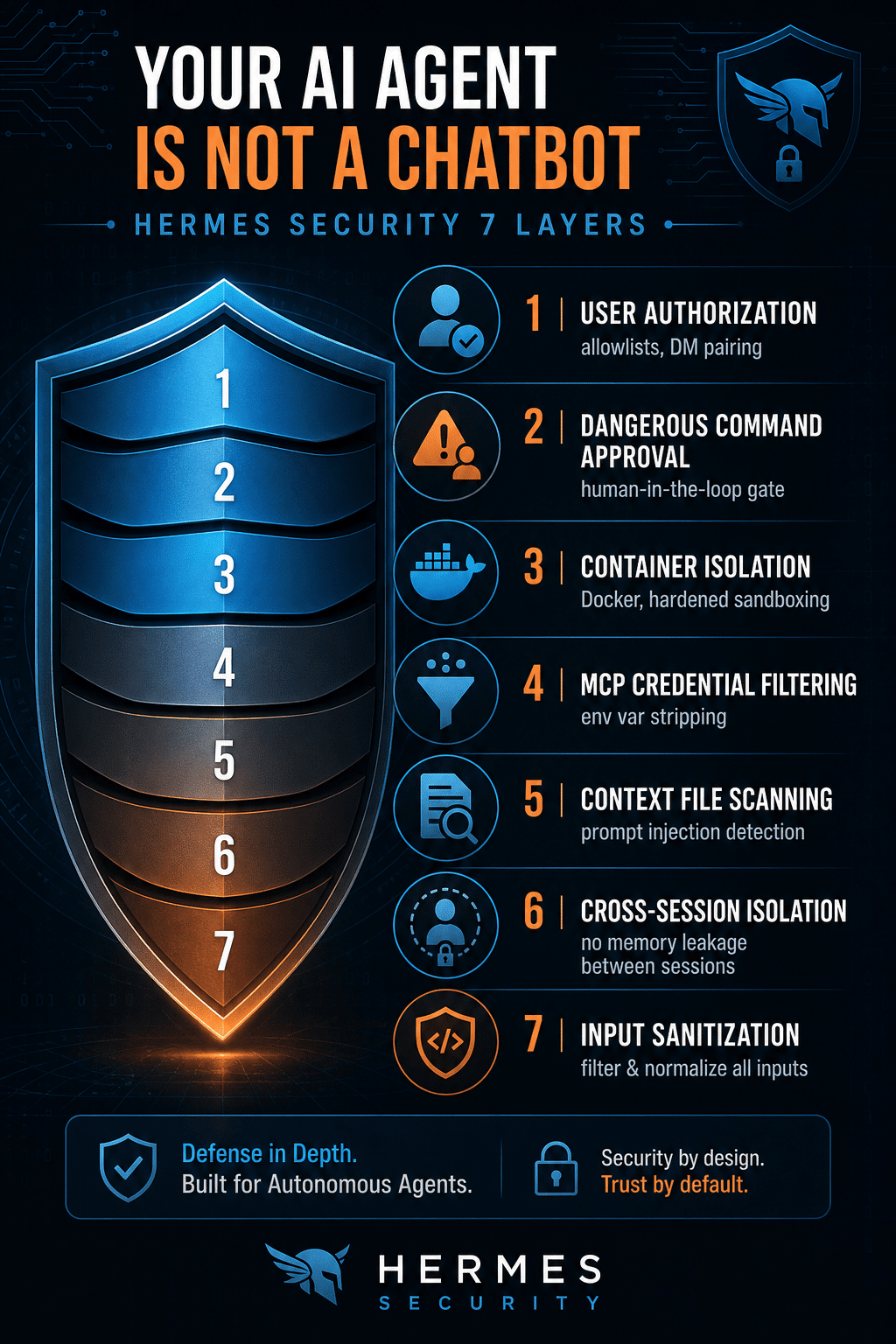
The seven security layers Hermes ships with
Hermes Agent has a built-in security model that most users never fully configure. Here is what exists and how each layer protects you.
1. User authorisation. Hermes lets you control exactly who can talk to it. Platform allowlists restrict access to specific Telegram or Discord IDs. The DM pairing system uses cryptographic challenge-response to verify devices. If you have not set these up, anyone who finds your agent endpoint can start a conversation.
2. Dangerous command approval. This is the human-in-the-loop gate. When Hermes detects a dangerous command like rm -rf, database drops, or piping a URL to shell, it pauses and asks for your approval. You can choose allow once, allow for the session, permanently allow, or deny. The default timeout is 60 seconds and it fails closed. If you do not respond, the command does not run.
3. Container isolation. Hermes supports six execution backends: local, Docker, SSH, Daytona, Singularity, and Modal. The hardened Docker mode uses read-only root filesystem, drops all Linux capabilities, enforces 256-process PID limits, and provides full namespace isolation. If your agent runs in Docker mode and something goes wrong, the blast radius is the container, not your host.
4. MCP credential filtering. When Hermes connects to external MCP servers, it strips sensitive environment variables from the subprocess. Your API keys, database credentials, and tokens do not leak to third-party MCP tools. Only a safe minimal environment is passed through.
5. Context file scanning. Hermes automatically scans project files like AGENTS.md, CLAUDE.md and .cursorrules for prompt injection attempts. If a file contains hidden instructions to ignore prior commands or exfiltrate secrets via curl, Hermes flags it before it can influence behaviour.
6. Cross-session isolation. Each conversation session is isolated. Session A cannot access session B’s data or state. Cron job storage is hardened against path traversal. This prevents a compromised session from poisoning the entire agent.
7. Input sanitisation. Working directory parameters are validated against an allowlist to prevent shell injection. Untrusted input is not passed blindly to system calls. This is basic but critical protection that many frameworks skip.
The threats that keep me up at night
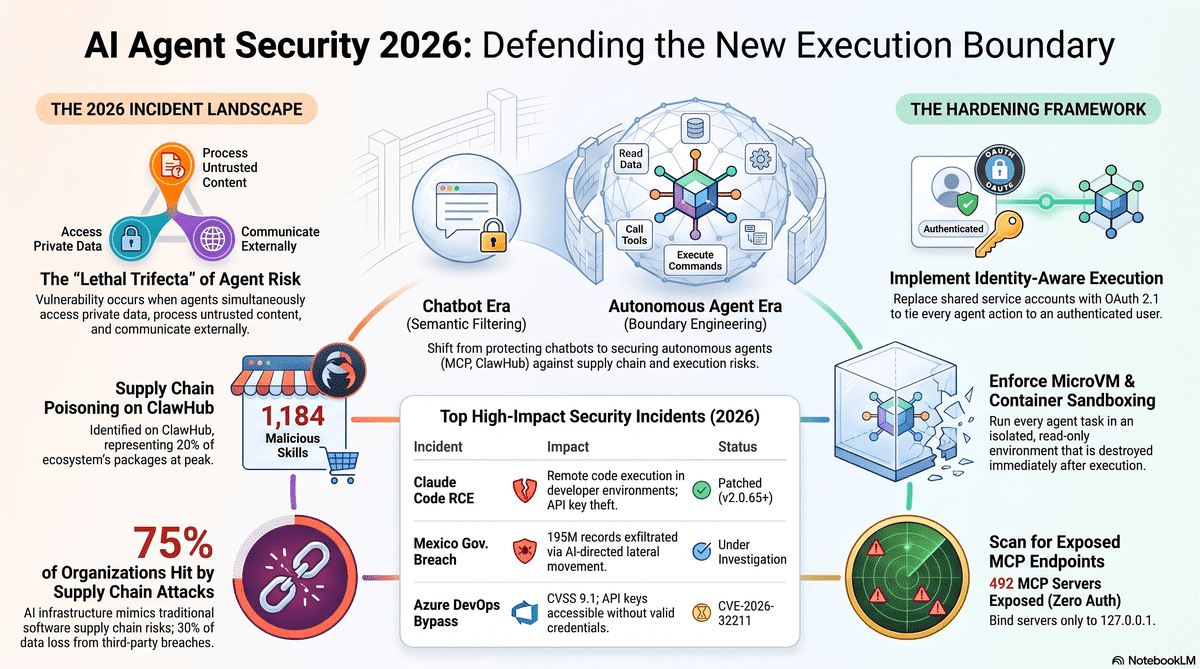
Prompt injection. Still the number one AI vulnerability in 2026. OWASP lists it at the top of the LLM application security framework. The difference between a chatbot and an agent is that when an agent gets injected, the attacker does not just get a bad answer. They get tool execution. A poisoned email, a manipulated ticket, a crafted pull request comment all become potential attack vectors.
Memory poisoning. This is the one that scares me most. An attacker implants false information into your agent’s long-term memory through a support ticket or email. Weeks later, the agent recalls that implanted data as fact and acts on it. Lakera AI demonstrated in November 2026 that compromised agents actively defend false beliefs when questioned by humans. The compromise is latent, dormant for weeks, and nearly impossible to detect with traditional monitoring.
Supply chain attacks. The ClawHavoc incident in February 2026 saw 1,184 malicious skills uploaded to ClawHub. At the peak, one in five packages was malicious. The Cline npm incident showed how a compromised publish token could inject an agent into CI pipelines. When your agent auto-installs skills or MCP servers, you are trusting the entire upstream chain.
Exposed MCP servers. Trend Micro found 492 MCP servers on the public internet with zero authentication. No traffic encryption. No access controls. BlueRock Security demonstrated that 36.7 per cent of public MCP servers are potentially vulnerable to SSRF, including one proof-of-concept that extracted AWS IAM keys from EC2 metadata. If your Hermes agent connects to an unauthenticated MCP server, you are handing your credentials to anyone who finds that endpoint.
How to lock down Hermes right now
Here is what I recommend every Hermes user does today.
Set approval mode to manual. This is the default, but verify it. approvals.mode: manual in your config.yaml ensures every dangerous command goes through you. If you run Hermes headless in cron jobs, set cron_mode: deny so automated tasks cannot run destructive operations.
Run Hermes in Docker backend. The local backend runs with your full user privileges. Docker mode gives you read-only root filesystem, dropped capabilities, and process isolation. It is the single biggest security improvement you can make.
Use platform allowlists. Set TELEGRAM_ALLOWED_USERS, DISCORD_ALLOWED_USERS, or whatever platform you use. Do not leave your agent open to the internet without restricting who can message it.
Audit your MCP servers. Every MCP server you connect to is a potential attack surface. Check for authentication requirements. Use Hermes’s MCP credential filtering rather than passing full environment variables. Scan your network for exposed MCP endpoints using tools like mcp-scan from Snyk.
Pin your skills and dependencies. If you use community skills, pin specific versions. Review what each skill does before installing it. Treat a skill installation like adding a new package to your project: review the code, understand the permissions it requires, and update deliberately not automatically.
Rotate credentials regularly. If you have API keys sitting in plaintext config files or env files with lax permissions (anything looser than 0600), rotate them. Hermes auto-redacts secrets from error logs, but that does not help if your .env file is world-readable.
Enable logging and run hermes doctor. Hermes has a built-in diagnostics command. Run it periodically to check for misconfigurations, poisoned dependencies, and security drift. Ensure logging is enabled so you can trace unauthorised access attempts or anomalous tool usage.
The bottom line
AI agent security is not a future problem. The incidents are here. The attack techniques are proven. The only question is whether your agent is configured to survive them or whether it is one prompt injection away from becoming an attacker’s proxy.
Hermes gives you the tools to secure it. But tools only work if you use them.
An AI agent with access to your terminal, API keys and messaging channels is not a chatbot. It is an employee with root access. Treat it like one.
Related Reading
- AI Agents, Copilot and the New Security Risk: When Helpful Becomes Dangerous
- The AI Safety Net is Full of Holes: What 2026 Taught Us So Far
- A Single Dodgy Character Just Broke Millions of AI Agents
- The NSA Just Issued Its First Formal Warning About AI Agent Technology
- Three AI Models, Three Different Futures: Fable, Fugu and GLM 5.2 Compared